
Epistemología, metodología y teorías
Ponencias
- Retos de la comunicación en la sociedad del conocimiento
- El documental como apuesta de investigación en comunicación
- Construcción del corpus para un análisis del estado del arte de la investigación sobre medios y mediaciones como temáticas en los estudios de comunicación y ciudad en Colombia, entre 2010 y 2015 (investigación en proceso)
- Reflexividad en los círculos de la palabra: de otras y otros a nosotras y nosotros
- Subcampo científico en la investigación en comunicación en Colombia
- La imagen en la era digital. Reflexiones filosóficas desde el arte
- Hacia un paradigma transdisciplinar y transcultural de la comunicación social
- Metodología relacional: más allá del nivel 1
- Comunicación para lo común: la apuesta académica del programa de Comunicación Social-Periodismo de la Universidad del Tolima
- El oficio del investigador: producción de objetos simbólicos
Metodología relacional: más allá del nivel 1
Olga Lucía Bedoya
Doctora en Ciencias Políticas de la Universidad Santiago de Compostela, España. Antropóloga de la Universidad de Antioquia. Profesora de la Universidad Tecnológica de Pereira.
olbedoya@utp.edu.co
Resumen
La presente ponencia es el producto de quince años de experiencia y reflexión sobre los vacíos que presentan los estudiantes de maestría o doctorado cuando enfrentan los análisis y síntesis de la información recopilada en los procesos investigativos. Para subsanar esos vacíos, se propone una metodología relacional, basada en la semiótica de Charles Sanders Peirce. El planteamiento se desarrolla a partir de ocho fases, que para el caso se denominan niveles de complejidad, y cuya idea podrá representarse como una espiral: así, cada vuelta nos lleva desde un lugar de menor complejidad a otro de mayor complejidad. El texto se estructura en función de las fases del proceso. Cada fase está acompañada por imágenes, que fungen como objetos del signo, o índices, como diría Peirce (1893-1913) en su teoría del signo. La imagen complementa y otorga mayor comprensión al texto; además, permite controlar la semiosis al infinito —donde cada idea lleva a otra, como diría el mismo Peirce—. Al final, esta propuesta metodológica relaciona dos momentos del proceso investigativo: la forma como se debe tratar la información para construir el dato y los softwares cualitativos, con el objeto de mostrar la mediación de la primera antes de abordar los últimos.
Palabras clave: signo, metodología relacional, semiosis al infinito.
Introducción
El tema central de la ponencia es la metodología relacional: más allá del nivel 1. El tema surge a partir de una vivencia personal que recoge más de 20 años de experiencia profesional —desde 1995— de dirección de más de 150 tesistas, entre estudiantes de maestría1 y doctorado2.
Producto de esa experiencia, se ha podido determinar que el mayor obstáculo a la hora de analizar los datos en las tesis es el trabajo con la información. Después de una ardua labor de recolección de datos (a través de técnicas como la encuesta, la entrevista, la observación, los test, entre otros), el estudiante no se sabe qué hacer con todo lo que ha recolectado, y se queda estacionado en un primer nivel de análisis. Así, los que usan las estadísticas, leen las tendencias, y los que utilizan el análisis textual, presentan tablas descriptivas; no obstante, ninguna de las dos formas de abordar el material recopilado muestran las relaciones entre los datos. Por ejemplo, la relación entre la tendencia y la no tendencia, que se puede inferir, o la comparación entre los tres valores de la campana de Gauss: el centro, el extremo izquierdo y el extremo derecho. Incluso, algunos estudiantes llegan a construir grandes bases de datos que admiten el manejo de dos o tres variables para analizar datos (v. gr. Excel), pero las relaciones son siempre simples. De modo que si el investigador demanda más de tres relaciones, no se pueden extraer de allí.
Ahora, con respecto del tratamiento del software cualitativo (v. gr. Atlas Tic y Nvivo), he notado que no hay comprensión sobre todo el potencial interpretativo que ofrecen las herramientas. Por lo tanto, el estudiante se queda en la primera parte de codificación libre, y presentan el informe desde allí. El escenario descrito, es al que llamo primer nivel.
La propuesta parte desde el convencimiento de que si no hay una mayor comprensión del proceso de análisis de los datos, no se pueden alcanzar mayores niveles interpretativos y, por ende, los resultados de la investigación serán más pobres. En otras palabras, el uso ineficiente de las herramientas estadísticas o tecnológicas deviene procesos investigativos taxativos y menos amplios.
Con el objeto de mitigar la situación descrita, he propuesto un proceso de lectura relacional de los datos, como paso previo al uso de las herramientas estadísticas y tecnológicas. El objetivo es que se comprenda el proceso de pensamiento y conocimiento en el tratamiento de la información.
Sustento teórico
Los procesos de pensamiento y de conocimiento que distingo en el análisis de datos los sustento en la Faneroscopia de Charles Sanders Peirce (Houser y Kloesel, 2012, p. 444), especialmente la semiótica o el tratamiento de signos, que en su concepción es tríadico. Decía Peirce (Houser y Kloesel, 2012, p. 61), que en el proceso del razonamiento, en general, intervienen los objetos y el razonamiento: los primeros, por lo general, hacen parte del conocimiento común, mientras que es por el segundo que alcanzamos una creencia, como resultado del conocimiento previo. En este proceso realizamos inferencias, que van más allá de las intuiciones. Esta forma de razonar es la que nos conduce a emitir juicios, que es el acto de conciencia de una creencia. A su vez, esta última es la que nos lleva a emprender acciones. De no tener conciencia, estaríamos entonces en un hábito simplemente.
Ahora bien, un juicio se expresa en proposiciones. Es en el juicio donde se muestra una unidad de pensamiento. Al llegar a este punto, Peirce introduce la idea de signo, pues es en él donde se manifiesta ese pensamiento. Así, para Peirce, el signo es:
Una cosa que sirve para transmitir conocimiento de alguna otra cosa y que está en lugar de ésta o la representa. Esta cosa se llama objeto del signo; la idea en la mente que el signo evoca, que es un signo mental del mismo objeto, se llama interpretante del signo (Houser y Kloesel, 2012, p. 63).
La cita nos refiere un proceso tríadico: 1) cosa, que sirve para transmitir conocimiento; 2) la cosa que está en lugar de, que es objeto del signo, y 3) la idea en la mente, que es aquello que el signo evoca. Se puede plantear entonces que en los objetos de los signos que comunicamos, se da un proceso de presencias/ausencias/presencias. Por lo tanto, las informaciones que recogemos en una investigación pueden tratarse como signos. Al hacerlo así, nos alejamos de la literalidad de los significados: pensar que lo que decimos es igual a lo que decimos. Pero no ocurre así con Peirce. Para él, en la presencia de lo que decimos está la ausencia de lo que no decimos. De allí que surja la pregunta: ¿Qué cosa está ausente, que se hace presente en el signo? Es una pregunta que en un primer nivel de análisis no se puede responder. De hacerlo, nos quedaríamos con el significado literal: la cosa es igual a lo que nombra (c = n).
Tomando como base estos planteamientos, construimos y proponemos una metodología que propende por hacer conscientes los procesos de razonamiento que se configuran en una investigación, para luego construir y comprender el dato que estamos analizando en la información recolectada, dato que se trata como signo.
Propuesta relacional: más allá del nivel 1
La propuesta relacional: más allá del nivel 1, se despliega en ocho fases3 que a continuación se presentan:
Fase uno: Sistematización básica de la información 4
Luego de recolectar la información —a través de los instrumentos seleccionados (encuesta, entrevista, observación, etc.)—, se procede a sistematizarla en tablas, bases de datos o cualquier otro instrumento de clasificación. En este punto la información aún está muy ligada a su fuente, es decir, se trata de no hacer ninguna conjetura, sino, como dice Deslauriers (2004, p. 10), dejarse encontrar por el dato. La Figura 1 recoge un ejemplo de la primera sistematización de la información
Figura 1. Ejemplo de la primera sistematización

Fuente: Vargas, 2017.
Fase dos: Conformación de grupos por palabras clave y relaciones
Al terminar el nivel uno, se procede a conformar campos semánticos con las palabras o las frases claves y su relación con el texto de recolección. Según el lingüista francés, Bernard Pottier (1992, p. 240), el campo semántico se define como los conjuntos que se puede formar a partir de compartir un rasgo común. La Figura 2 presenta un ejemplo de campo semántico
Figura 2. Ejemplo de campo semántico.

Fuente: Vargas, 2017.
Fase tres: formación de grupos
Tras identificar las palabras o frases que aglutinan información similar, según las relaciones establecidas en el mismo documento, se procede a formar grupos. La Figura 3 muestra un ejemplo de agrupación.
Figura 3. Ejemplo de formación de grupos.

Fuente: Vargas, 2017.
Fase cuatro: nuevas agrupaciones
Cuando se observa el proceso que hasta aquí se ha desarrollado, encontramos datos repetidos, con significado similar y dispersos. Es por ello que se requiere establecer otro tipo de relaciones, para ir concentrando más la información, dado que su dispersión nos puede conducir a inferencias débiles o redundantes, es decir, que respondan a los mismos datos. Es una situación no conveniente y que denota falta de abstracción. La Figura 4 reproduce otra agrupación, concentrando más el dato.
Figura 4. Ejemplo de nueva agrupación
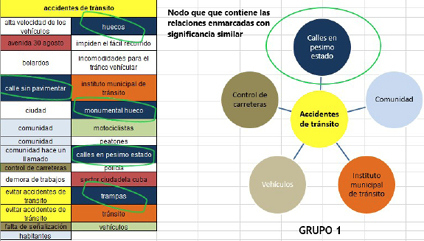
Fuente: Vargas, 2017.
Siguiendo este proceso, con la información de la fase 3, y con la forma de aglutinar los datos de la fase 4, queda la información agotada en estas relaciones, como se presenta en la Figura 5:
Figura 5. Ejemplo de agrupaciones
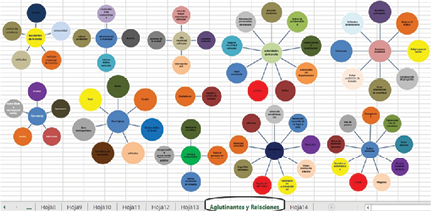
Fuente: Vargas, 2017.
Para pasar al nivel 5, se requiere extraer el dato de la pantalla y trasladarlo a un espacio físico (una impresión del contenido, si se ha realizado en el computador). Como a estas alturas del análisis se requiere mayor abstracción y una conexión con lo que estoy buscando en la investigación, el papel es el mejor sustrato para trabajar. En la pantalla, la visión es lineal, de arriba abajo, rasgo que no permite ver holísticamente todo el dato y gozar de una vista panorámica de lo organizado hasta el momento. La visión panorámica asegura una adecuada saturación de la información, y nos faculta para pasar a determinar cuáles son los objetos del signo de la investigación que estoy llevando a cabo, y su relación con los autores.
Fase cinco: nueva concentración del dato a partir de la periferia no del centro
Cuando ya tenemos una mirada panorámica de todo lo que hasta el momento hemos construido, observamos todos los nodos, con sus respectivas agrupaciones, y hacemos énfasis, ya no en el centro del nodo sino en la periferia (pétalos de la flor). Esta labor reaglutina la información, pero sin un centro o punto convergente, sino que se forman otros grupos por lo que comparten. Las Figuras 6 y 7 recogen estas agrupaciones a partir de la periferia.
El fin de esta fase es eliminar la redundancia de información, agotar las semejanzas, y observar qué dato no tiene ninguna relación con los demás. Como dice Vargas (2017):
Se trata de volver a considerar los elementos que hacen parte de las mismas categorías, de verificar si están en su lugar o sino (sic) debiesen estar en otra parte, de aprobar las categorías mismas y de apuntar a su fusión con otras o su subdivisión (p. 34).
Una vez disgregados los nodos —como ya lo habíamos anunciado—, se forman otras relaciones. La consecuencia es descubrir que varios datos, ubicados en la periferia de los nodos (pétalos), tienen similitud con otros de los demás nodos. Ejecutar esta labor de desagrupación/reagrupación hace que los datos marginados, mas todo aquello considerado residuo (es decir, información aparentemente sin relación), pueda ser objeto de una nueva reagrupación que los considere.
Figura 6. Ejemplo de reagrupación a partir de la periferia.

Fuente: Vargas, 2017.
Figura 7. Ejemplo de la manera de agrupar a partir de la periferia
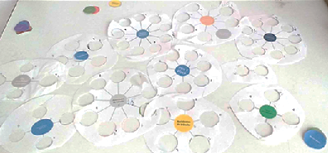
Fuente: Vargas, 2017.
Fase seis: agrupaciones y residuos
El investigador en esta fase necesita agudizar más su observación. Para que pueda hacer las distinciones respectivas, el investigador requiere mayor nivel abstracción, de proceso de razonamiento. Solo así podrá avanzar a las ausencias presentes en los datos considerados como signos. La Figura 8 condensa las agrupaciones y los residuos (datos sin relación aparente).
Figura 8. Ejemplo de agrupaciones-residuos
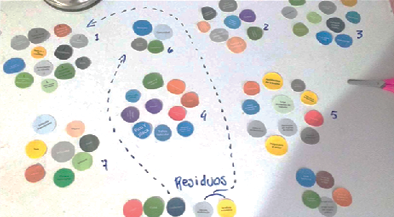
Fuente: Vargas, 2017.
Fase siete: inclusión de los residuos en los grupos formados
Como se observa, en la fase 6 hay información que hasta ese momento se considera todavía como residuo, es decir, que no tiene nada que ver con el resto de la información. Pero tras observarla con mayor detenimiento, se encuentra que puede agruparse en función de los rasgos que comparte con los otros grupos. De esta manera se consigue formar solo grupos parecidos, sin nada que sobre (residuo).
Como resultado de todo el proceso, se logra una síntesis que considera todas las dispersiones de una información que, aparentemente, era exagerada (Figura 9). Y ahora, a partir de aquí, es necesario pasar a otro nivel.
Figura 9. Ejemplo de la síntesis de todo el dato

Fuente: Vargas, 2017.
Fase ocho: relación hallazgos con pregunta de investigación y teoría
En esta fase, el investigador debe usar su capacidad, no solo abstractiva sino teórica, para dar respuesta argumentativa a la creencia con la que inició su investigación. Por ejemplo, una primera sospecha es aquella que sugiere «que la percepción de los ciudadanos de la ciudad de Pereira, sobre la calidad del tráfico era regular». Entonces, el investigador se preguntaba, ¿qué posibles índices podrían haber llevado a estos ciudadanos a percibir el tráfico de esta manera? ¿Cuál(es) eran los objetos ausentes que se hacen presentes en la representación? Las dos preguntas se formularon en el marco de la teoría del signo de Peirce y la teoría de los imaginarios urbanos de Armando Silva Téllez.
En esta primera conexión con la teoría, se puede inferir que la cosa ausente en la percepción ciudadana es la calidad del tráfico en la ciudad de Pereira, y que las conexiones presentes que la idea genera son: a) el estado de vías y carreteras, b) los medios de transporte —y su falta de movilidad—, c) los accidentes de tránsito y, d) la normatividad-agentes. Ahora, si se quiere mirar los detalles, detrás de cada uno de estos índices se halla la información que sustenta el juicio emitido.
Llegado a este punto, el investigador ya puede seguir subiendo el nivel teórico de las conexiones (imaginarios urbanos, construcción social de la realidad, antropología ciudadana, diseño de ciudad, etc.), según el interés que le generen estos resultados, tanto a nivel teórico como práctico. Esto último tiene que ver con sus objetivos y con el aporte que desea hacer con su investigación.
Relación entre la metodología relacional: más allá del nivel 1 y el software cualitativo
Nuestra afirmación es la siguiente: para usar un software cualitativo, es necesario comprender el proceso que subyace en las herramientas que nos presentan estos software. La premisa es que si no comprendemos, nos quedamos en el nivel 1 o herramienta uno —quizás dos—. Por ejemplo, el software Nvivo nos presenta dos grandes fases: la primera ofrece los pasos que el investigador utiliza para construir su proyecto: documentos (textos, memos, reflexiones), nodos (ideas, categorías, conceptos, gente, cosas) y atributos (de documentos, o nodos); la segunda presenta el proceso de combinación de la construcción anterior, donde se tiene el enlace entre los datos, la codificación en nodos, la forma que toman los datos y su ramificaciones. Este recorrido permite ir modelando los datos para poder buscar luego en ellos (Richards, 2000, p. 6).
Si miramos el lenguaje usado en Nvivo, encontramos una lógica —o arte de razonar, como dice Peirce (Houser y Kloesel, 2012, 62)— para llegar a inferencias, que luego se convertirán en argumentaciones que se expresarán en razonamientos, que finalmente conducirán a conclusiones. Si el investigador no ejercita estas habilidades del pensamiento y el conocer, difícilmente podrá lograr un avance en los procesos investigativos, de tal suerte que no será ni sistemático ni hábil para usar estos software.
En conclusión, la metodología relacional propuesta es un camino intermedio entre el investigador y los software, que lo conduce a concienciarse de su creencia inicial y generar nuevos hábitos conscientes de razonamiento.
Este es el aporte que se quiere dejar con esta ponencia.
Referencias
Bedoya, O. (2014). Protocolo de análisis de datos (no publicado). Universidad Tecnológica de Pereira, maestría en Comunicación Educativa, Pereira, Colombia.
Deslauriers, J. (2004). Investigación cualitativa: Guía práctica. Pereira: Papiro.
Houser, N. y Kloesel C. (Comp.). (2012). Obra filosófica reunida: Charles Sanders Peirce, Tomo III (1893-1913). México: Fondo de Cultura Económica.
Pottier, B. (1992). Sémantique générale. París: Presses Universitaires de France.
Richards, L. (1999). Using NVivo in Qualitative Research. London: SAGE Publications.
Vargas, H. (2017). ¿Calidad del tráfico en Pereira?: entre las presencias y ausencias. (Tesis de maestría en Comunicación Educativa no publicada). Universidad Pereira, Pereira, Colombia.
1 Maestría en Comunicación Educativa.
2 Doctorado en Ciencias de la Educación.
3 Incluso al interior de estas 8 fases, se pueden construir subfases, èsto de acuerdo a la necesidad de comprensión del mismo estudiante.
4 Las tablas, gráficos, y demás propuesta visual que se utiliza como medio para ilustrar lo que se explica con palabras, fueron cedidas por el tesista de Maestría en Comunicación Educativa (2017), Hugo Vargas, quien precisamente, utilizo el protocolo para el análisis/síntesis/argumentación de su tesis, como otros cuantos durante el proceso de validación del mismo.